
この連載「Pythonプログラミングの始め方」では、大人気Pythonを扱う上で知っておきたい、基礎文法を図解を交えて分かりやすく解説していきます。Python学習の一助にしていただければ幸いです。
今回はPythonの内包表記によるリスト・辞書・セットを定義する方法について解説していきます。
内包表記は、他言語にはないPython特有のコーディングスタイルでfor-in構文と[],{}を組み合わせて、リスト・辞書・セット、それからジェネレータの定義を1ステートメントで完結に表記できます。(タプルは内包表記できません。)
内包表記で記述するメリットとして、以下があります。
※本質的ではないととは、for文句や制御用の変数といった「本来の機能」の目的にとって重要でないことを指します。
以上のような、利点があるのでPythonでは「内包表記」はごく当たり前のように使われるコードスタイルです。ですので、コードを書く、他の人の書いたコードを解読するといった場合はこの内包表記の書き方を知っておく必要があるのです。
Python公式ドキュメントの内包表記に関する記述は、以下になりますので必要に応じて参照してください。
Python公式ドキュメント(リストの内包表記)の引用
https://docs.python.org/ja/3/tutorial/datastructures.html#list-comprehensions
また、リストや辞書といったデータ構造そのもののについては、以下の記事で取り上げています。こちらも参考にしてみて下さい。


それでは、次節より具体的な書式の解説をしていきます。まずは「内包表記の基本形」からはじめ、発展形として、「多重構造・条件分岐付き表記」について取り上げていきます。
1. 内包表記の基本形

内包表記はデータ構造の「リスト」「辞書」「セット」「ジェネレータ」に対応するコードスタイルです。(ただし、タプルだけは内包表記で記述できません。) 各種オブジェクトを定義するには、いくつかの書式やパターンがあります。ここでは、内包表記の「基本形」についてそれぞれ解説します。
1.1 リスト・辞書・セットの内包表記
内包表記の基本書式を定義するデータ構造(リスト・辞書・セット・ジェネレータ)ごとに示します。対象のデータ構造ごとに[],{}や式の部分などに違いがありますが、基本的な書式はどれも同じです。
イテラブルには、シーケンス型のオブジェクトを置きます。たとえば、リスト・Rangeオブジェクト・ZIPオブジェクト・タプル・文字列 などが該当します。
リスト
[ 式 for 変数 in イテラブル ]
辞書
{ キー:式(値) for キー in イテラブル }
セット
{ 式 for 変数 in イテラブル }
ジェネレータ
( 式 for 変数 in イテラブル ) ※
※ タプルの内包表記ではありません
イテラブル には、リストやRangeオブジェクト、文字列、タプル、ZIPオブジェクトなど
シーケンス型のオブジェクトを指定します。
戻り値:新しく定義されたオブジェクト
書式だけだと分かりずらいかもしれませんね。内包表記の処理の流れを図示します。
次はリスト(とセット)の内包表記の概略図です。両者の書式はほぼ同じで[]で囲むか、{}で囲むかの違いしかありません。(図1)
- イテラブルなオブジェクト(リストやRange)を順次展開する。
- 一時的に変数に格納する。
- ➁を使った式で評価した値を要素として、新しいリスト(セット)を生成する。

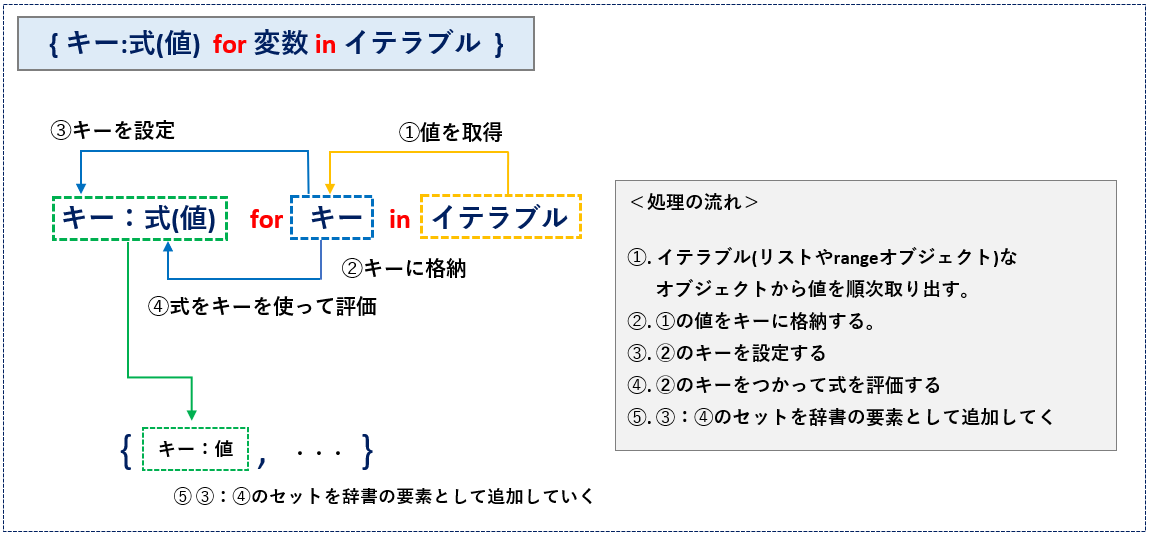
次は、辞書の内包表記です。リスト(セット)との違いは「式」の部分が辞書の要素の組合せである「キー : 値」になっている部分です。(図2)
- イテラブルなオブジェクト(リストやRange)を順次展開する。
- 一時的に変数(キー)に格納する。
- ➁の変数をキーや式で評価する。
- キー:式(値)の形式で辞書の要素として追加される。
この他、ジェネレータの内包表記もありますが、「活用頻度がそれほど高くないこと」と「タプルの表記と混同することがある」ので本記事では解説を省略します。
それでは、実際にコードで確認してみましょう。
次の<List1>は、内包表記のイテラブル部に指定した「リストオブジェクト」が順次展開されます。その後<式>で再評価され、新たなリスト・セット・辞書の要素として追加されていきます。
# イテラブルなオブジェクトに「リスト」を指定した場合
nums = [1, 2, 3, 4, 5]
keys = ['apple', 'orange', 'pine','avocado']
#-----------------------------------------------------------------------
# リストの内包表記
# リストnumsの各要素を2倍にしたリストを作成する
nums_double = [ num * 2 for num in nums ]
print(nums_double) # ➀>> [2, 4, 6, 8, 10] 新しいリストが作成された
#-----------------------------------------------------------------------
# セットの内包表記
# リストnumsの各要素を3倍にしたセットを作成する
nums_double = { num * 3 for num in nums }
print(nums_double) # ➁>> {3, 6, 9, 12, 15} 新しいセットが作成された
#-----------------------------------------------------------------------
# 辞書の内包表記
# リストkeysの各要素をキーとし、キーの長さを値とする辞書を作成する
dict_out = { key:len(key) for key in keys }
print(dict_out) # ➂>> {'apple': 5, 'orange': 6, 'pine': 4, 'avocado': 7} 新しい辞書が作成された内包表記(イテラブルに「リスト」を指定)
➀ 》 [2, 4, 6, 8, 10] # リスト(元の要素の2倍で再定義)
➁ 》 {3, 6, 9, 12, 15} # セット(元の要素の3倍で再定義)
➂ 》 {‘apple’: 5, ‘orange’: 6, ‘pine’: 4, ‘avocado’: 7} # 辞書(キー:キーの字数)
次にRangeオブジェクトを展開する内包表記の例です。<List2>Range()関数は「開始:終了:ステップ」のように展開する値の範囲とステップ幅(省略可)を指定します。
# イテラブルなオブジェクトに「Rangeオブジェクト」を指定した場合
#----------------------------------------------------------------------
# リストの内包表記
nums = [ num for num in range(1, 5) ]
print(nums) # ➀>>[1, 2, 3, 4]
#-----------------------------------------------------------------------
# 辞書の内包表記
dict_out = { key : (key * 2) for key in range(1, 10, 2) }
print(dict_out) # ➁>>{1: 2, 3: 6, 5: 10, 7: 14, 9: 18}内包表記(イテラブルに「Rangeオブジェクト」を指定)
➀ 》 [1, 2, 3, 4] # リスト(1~5を展開)
➁ 》 {1: 2, 3: 6, 5: 10, 7: 14, 9: 18} # 辞書(1~10を2個飛ばしのキーと2倍した値)
また、文字列もシーケンス型の一種ですので、内包表記の書式で展開することができます。<List3>
# イテラブルなオブジェクトに「文字列シーケンス」を指定した場合
#-------------------------------------------
# リストの内包表記
str_list = [ str + "_class" for str in "ABCD" ]
print(str_list) # ➀>> ['A_class', 'B_class', 'C_class', 'D_class']
#-----------------------------------------------------------------------
# 辞書の内包表記
dict_out = { key : ord(key) for key in "ABCD" }
print(dict_out) # ➁>> {'A': 65, 'B': 66, 'C': 67, 'D': 68}内包表記(イテラブルに「文字列シーケンス」を指定)
➀ 》 [‘A_class’, ‘B_class’, ‘C_class’, ‘D_class’] # リスト(A,B,C,Dを展開)
➁ 》 {‘A’: 65, ‘B’: 66, ‘C’: 67, ‘D’: 68} # 辞書(A,B,C,Dをキーとし、文字コードを値とする)
そして、最後に zip()関数 から「zipオブジェクト」を生成し、イテラブルに変数へ展開します。zip()関数は、複数のリストをタプルとしてまとめることができます。タプルは、一度に複数の変数に展開が可能で<List4>では、変数を2つ並べています。(詳細は zip()関数 を参照下さい。)
# イテラブルなオブジェクトに「zipオブジェクト」を指定した場合
str1 = ["A", "B", "C"]
str2 = ["_a", "_b", "_c"]
#---------------------------------------------------------------------------------------
# リストの内包表記
# Zipオブジェクトは、複数のリストをタプル型式に変換したもの
# Zipオブジェクト2つの変数に展開して、式で再評価して要素に追加する
list12 = [ s1 + s2 for s1, s2 in zip(str1, str2) ]
print(list12) # ➀>> ['A_a', 'B_b', 'C_c']
内包表記(イテラブルに「Zipオブジェクト」を指定)
➀ 》 [‘A_a’, ‘B_b’, ‘C_c’] # リスト(2つのリストを連結(同じインデックス同士)させた要素とする)
以上が、内包表記の基本形の解説となります。ここまでの解説で、既にお気づきかもしれませんが、内包表記といってもやっていること(できることは)「For-in構文」と同じです。
リストや辞書の書式の中に、式を記述し1行で簡潔に表現しているだけですが「処理が早くなる」「インデントが減る(可読性が良くなる)」といったメリットを享受することができるのです。
2. 内包表記の発展形

<1節>では、内包表記の基本形について解説しましたが、これ以外にも「発展形」として「For文句を2重構造にしたもの」や「if文句による条件判定を組合わせたもの」があります。
より複雑な論理ステートメントを1行にまとめて表現することができ、Pythonらしい記述スタイルが可能となります。ただし、逆に可読性が低下することもありますので、用途に応じて適切に使い分けましょう。
2.1 「for文句」がネストされた内包表記
内包表記の基本形をより発展させて「For-in句」の2重化(ネスト)して使う記述スタイルがあります。たとえば、「リストの要素がリスト」や「リストの要素が文字列」であったりした場合など、イテラブルの多重構造を効率的に展開することができます。
このスタイルの内包表記も、リスト・セット・辞書・ジェネレータの4種類のオブジェクトに対応します。以下に、各オブジェクトごとの書式を示します。
リスト
[ 式 for 変数A in イテラブル for 変数B in 変数A ]
辞書
{ キー:式(値) for 変数 in イテラブル for キー in 変数 }
セット
{ 式 for 変数A in イテラブル for 変数B in 変数A }
ジェネレータ
( 式 for 変数A in イテラブル for 変数B in 変数A )
イテラブル には、リストやRangeオブジェクト、文字列、タプル、ZIPオブジェクトなど
シーケンス型のオブジェクトを指定します。
戻り値:新しく定義されたオブジェクト
書式の概要を図解すると次のようになります。(図3)
リスト・セット・辞書いずれも、「for-in句」がネストされている部分のみが、先の基本形とはことなります。ですので、図3ではリストを例に図解しています。for-in句が並んだ場合は、まず左側のfor-in句が最初に展開され、次に右側のfor-in句に渡されてさらに展開されるといった処理になります。

実は、ネストされる「for-in句」の数は2重、3重・・・と連ねることができますが、構造が複雑となり可読性が著しく低下しますので、あまりお勧めしません。
ネストは2重程度に限定するのが一般的な記述スタイルです。
具体例で確認したほうが理解しやすいので、2例ほど紹介します。
イテラブルなオブジェクトとして「リストの要素がリスト」と「リストの要素が文字列」であった場合の内包表記となります。「for-in句」の展開フローに着目してください (左側→右側の順番で展開されるのでした)。<List5>
# For文句がネストされた内包表記
# リストを要素にもつリストを展開
numbers = [ [1, 2], [3, 4], [5, 6] ]
#--------------------------------------------------------------------------
# リストの内包表記(For-in句のネスト型)
list_result = [ num_b*2 for num_a in numbers for num_b in num_a ]
print(list_result) # ➀>> [2, 4, 6, 8, 10, 12]
#--------------------------------------------------------------------------
# セットの内包表記(For-in句のネスト型)
set_result = { num_b*2 for num_a in numbers for num_b in num_a }
print(set_result) # ➁>> {2, 4, 6, 8, 10, 12}
#--------------------------------------------------------------------------
# 辞書の内包表記(For-in句のネスト型)
dict_result = {num_b : 'No.'+str(num_b) for num_a in numbers for num_b in num_a}
print(dict_result) # ➂>> {1: 'No.1', 2: 'No.2', 3: 'No.3', 4: 'No.4', 5: 'No.5', 6: 'No.6'}
#--------------------------------------------------------------------------
# 文字列を要素にもつリストを展開
strings = ['AB', 'CD', 'EF']
list_result2 = [ str_b * 2 for str_a in strings for str_b in str_a ]
print(list_result2) # ➃>> ['AA', 'BB', 'CC', 'DD', 'EE', 'FF']
For文句がネストされた内包表記
➀ 》[2, 4, 6, 8, 10, 12] # リスト
➁ 》{2, 4, 6, 8, 10, 12} # セット
➂ 》{1: ‘No.1’, 2: ‘No.2’, 3: ‘No.3’, 4: ‘No.4’, 5: ‘No.5’, 6: ‘No.6’} # 辞書
➃ 》[‘AA’, ‘BB’, ‘CC’, ‘DD’, ‘EE’, ‘FF’]
もう一つ応用として、次の<List6>のように「内包表記の内側にさらに内包表記を」といった書き方もできます。処理される順番は、まずは外側のfor-in句が最初に展開され、その次に内側のfor-in句が処理対象となります。
<List6>は、多重(2次)リストのオブジェクト構造を変更することなく、新しい、再演算されたリストオブジェクトを生成する例となります。
# For文句の2重化による内包表記
# リストを要素にもつリストを展開
numbers = [ [1, 2], [3, 4], [5, 6] ]
#--------------------------------------------------------------------------
# 内包表記の中に、内包表記を記述するスタイル
# 外側のfor-in句が先に展開され、次に内側が展開される順番で処理される
list_result=[ [ num_b*2 for num_b in num_a ] for num_a in numbers ]
print(list_result) # ➀>> [[2, 4], [6, 8], [10, 12]]
内包表記の中に内包表記
➀ 》[[2, 4], [6, 8], [10, 12]]
以上、内包表記のfor-in句のネスト構造についての解説しました。基本型に比べると複雑な構造となりますが、1行で簡潔にコードを記述できる点はメリットがあります。(基本形よりもインデント削減効果がおおきくなります。)
処理自体にあまり重要な意味を持たない箇所は、積極的に活用すると良いと思います。
2.2 条件分岐(if文句)付きの内包表記
内包表記にif文による条件分岐式を付加することで、条件を満たす要素のみを、新規オブジェクトに追加することができます。
(特定の条件でフィルタリングされた要素のみを新規オブジェクトに追加できる。)
書式は以下の通りで、<1節 (基本形)>や<2.1項 (ネスト型)>にif文句を右側に付加します。ちなみに、else句を繋げることはできませんが、さらにif文句を並べて追加することもできます。(その場合は、左から右へ順番に判定されます。また「;」や「;」で区切ることはできません。)
リスト
[ 式 for 変数 in イテラブル if 条件式 ]
辞書
{ キー:式(値)for キー in イテラブル if 条件式 }
セット
{ 式 for 変数 in イテラブル if 条件式 }
イテラブル には、リストやRangeオブジェクト、文字列、タプル、ZIPオブジェクトなど
シーケンス型のオブジェクトを指定します。
戻り値:新しく定義されたオブジェクト
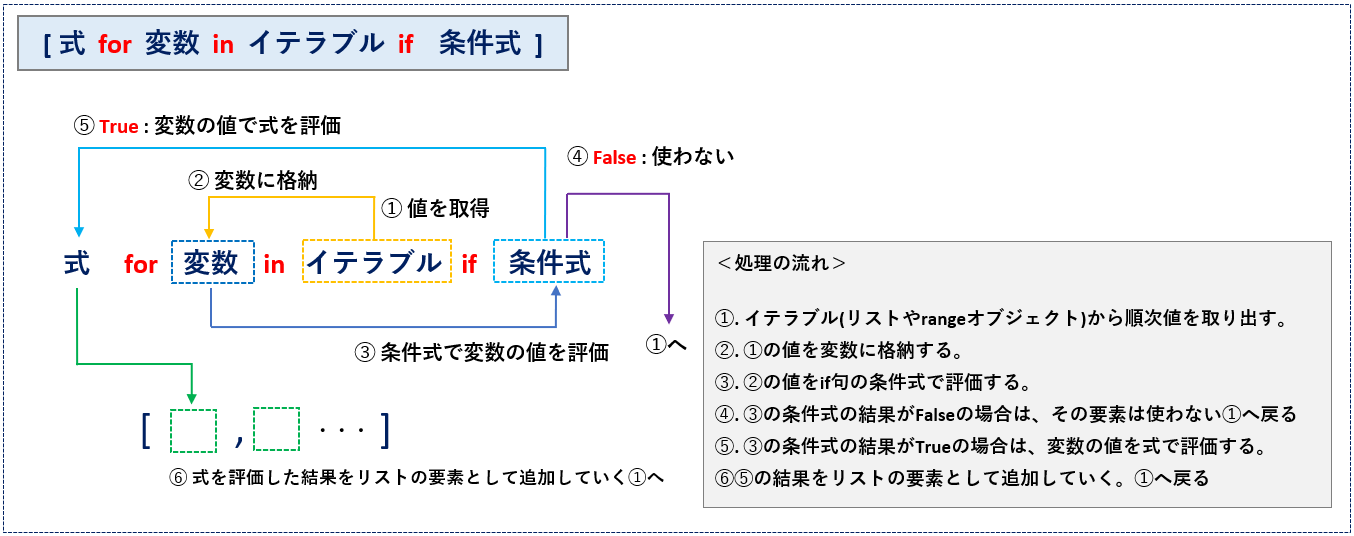
書式の概要を図解すると次のようになります。(図4)
if文が成立しない要素はスルーされます(➂, ➃)。
リスト・セット・辞書いずれも同様ですので、図4ではリストを例にしています。
それでは、コード例を紹介します。<List7>では、if文句(0以上3未満、5文字)が成り立つ要素について、式で評価されて新しいリストや辞書を生成しています。
# 条件式付き内包表記(1)
numbers = [-1, 0, 1, 2, 3, 4, 5]
words = ['Japan', 'America', 'Chine', 'England']
# -----------------------------------------------------------------------------
# 条件式(0以上3未満)が成り立つ要素を2倍する
result = [ num * 2 for num in numbers if (0 <= num < 3) ]
print(result) # ➀>> [0, 2, 4]
# 条件式(文字数が5文字)が成り立つ場合に追加する
result = [ word for word in words if len(word) == 5 ]
print(result) # ➁>> ['Japan', 'Chine']
# -----------------------------------------------------------------------------
# 条件式(文字数が5文字)が成り立つ場合、要素をキーとし、文字数を値とする辞書
result = { key : str(len(key))+'文字' for key in words if len(key) == 5 }
print(result) # ➂>> {'Japan': '5文字', 'Chine': '5文字'}
条件式付き内包表記(1)
➀ 》[0, 2, 4]
➁ 》[‘Japan’, ‘Chine’]
➂ 》{‘Japan’: ‘5文字’, ‘Chine’: ‘5文字’}
また、if文句は1つだけではなく、複数個並べることができるのでした。<List8>では、5以上でかつ偶数である要素を、2つのif文で判定しています。この例のように、if文は2程度であればよいのですが、それ以上になるととたんに可読性が低下しますので気を付けましょう。
# 条件式付き内包表記(2)
numbers = [4, 12, 21, 32, 8, 6, 11, 16]
# 条件式(5以上の偶数)が成り立つ要素をもつ新たなリストを作る
result = [ num for num in numbers if num>=5 if num%2==0 ]
print(result) # ➀>> [12, 32, 8, 6, 16]
条件式付き内包表記(2)
➀ 》[12, 32, 8, 6, 16]
3. まとめ

いかがでしたでしょうか?
今回は、Pythonの内包表記について解説をしました。内包表記は他のプログラミング言語には見られない特殊な書き方なので慣れるまでは戸惑いますが、複数行の処理を1ステートメントに記述できるためコードがスッキリとし、可読性が高まります。
また、処理が少し速まるというメリットもありPythonでは好んで使われる書き方の一つとなります。
今回の記事を是非、お役立てくださいますと幸いです。
最後までお読みいただきありがとうございました。